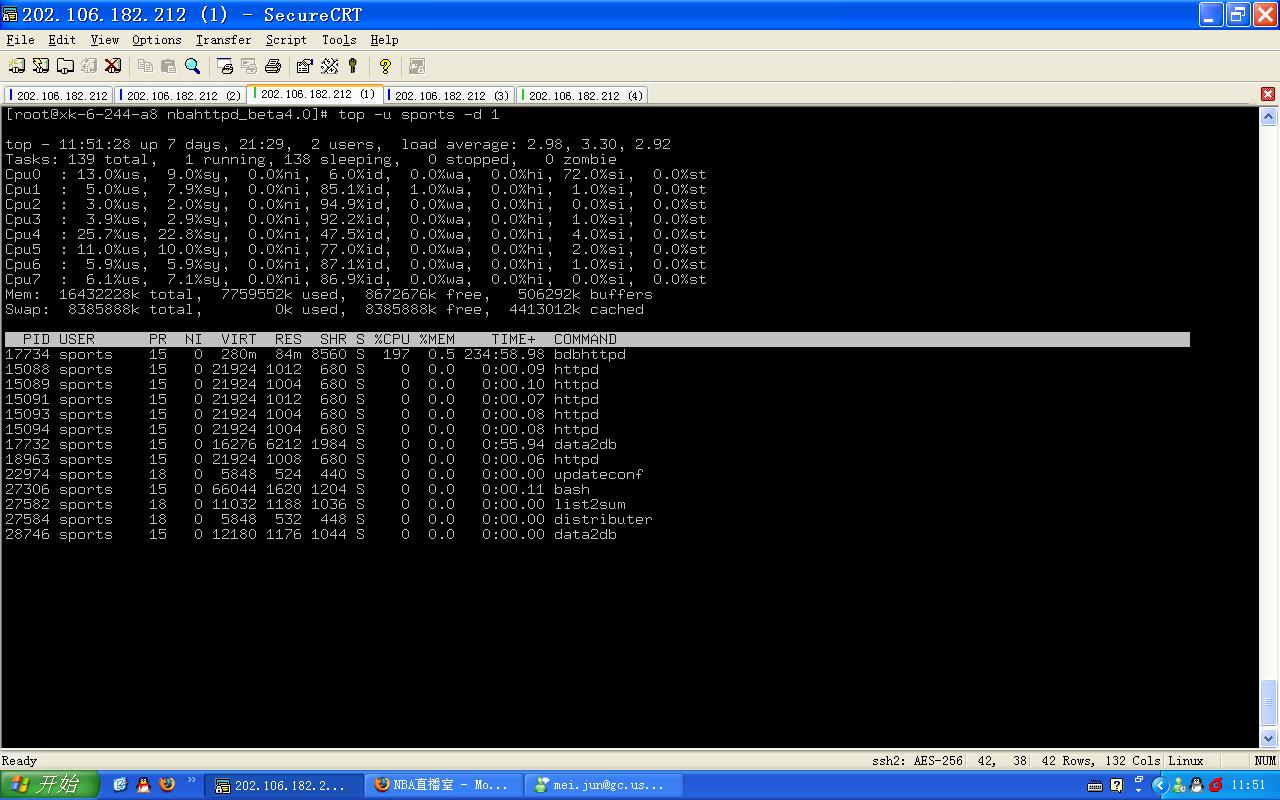
用于高负载,高读写速度的单点和集合数据。内核为BerkeleyDB,外壳为UDP线程池。接口为读写单点数据或者集合数据。单点数据就是Key->Value数据。集合数据就是有索引的数据,List->Keys->Values。比如一个班级所有成员,一个主贴所有回帖等等。 DBDS性能很高,每秒读取>800个每秒,写>300个每秒(志强xeon:2G*2,72Gscsi,Ram:2G)配合java接口,目前应用在ChinaRen所有项目中(ChinaRen校内,校友录,社区等等)。是整个ChinaRen的核心数据服务,大概配备了50台服务器。特点:高速,高请求量。用于各种数据的低成本存储,解决数据库无法实现超高速读写的问题。门户级别的高速数据服务。
OnlineServer:
ChinaRen/SOHU小纸条系统核心核心为3个小server系统:online2(在线系统业务逻辑),userv(用户资料系统),cserv(LRU缓存) 这三个子系统都是UDP+线程池结构,单进程+多线程。配备java接口,apache_mod的json和xml接口。 online2包括了大部分业务逻辑,包括,上线,好友系统,纸条系统。 userv包括设置用户各种属性,信息。 cserv是个大的lru缓存,用于减小磁盘IO。可以放各种信息块,包括用户信息,好友,留言等。目前配备4台服务器(DL380,xeon:3G*2,SCSI:146G raid,Ram:2G),用户分布到4台服务器上,相互交互。服务器可以由1台到2台,到4台,到8台。底层存储为文件存储(无数据库),用reiserfs。配套系统: mod_online,两个版本,apache和lighttpd版本,用于页面上显示蜡烛人。请求量巨大,目前用lighttpd版本的mod_online。放在sohu的squid前端机器上,运行在8080,大概8台,每台请求量大概500-800个每秒。蜡烛人在所有ChinaRen页面有ID的地方显示用户是否在线。目前这套在线系统,作为SOHUIM的内核原型。准备开发WEBIM系统,用户所有SOHU矩阵用户的联络。
apache_mod
cserv:
高速LRU缓存系统。内核是UDP+线程池+LRU结构(hash+PQueue)。用于存放各种数据块,Key->Value结构。通过LRU方式提供给应用,可减小文件IO,磁盘IO等慢速操作。目前用于ChinaRen在线系统的用户资料缓存。特点:高速读写,低成本。
ddap:
UDP+线程池,单进程,多线程的服务端程序原型,大部分程序由这个结构开始。性能为8000-10000个请求每秒。
eserv:
访问统计系统用于用户访问的次数和最后上线时间的存储和读写。用于ChinaRen校友录每个班级的访问记录。存储为文件存储,并有同时写入后备的bserv,用于备份和检索。目前性能,每台机器每秒50个记录,100个读每秒。能满足校友录巨大的用户登录记录的需要。特点:无数据库,纯文件存储,高速读写。低成本
logserver:
用于各种事件的日志记录核心为ddap,UDP+线程池功能是分模块记录各种日志。ChinaRen所有用户服务,系统日志,都记录在logserver中。用于统计,查询。写入性能很好,每秒100个单台机器。特点:高速高效,低成本,海量。
SessionServ:
session系统核心为ddap,UDP+线程池用于在内存中存储临时数据。有get/put/del/inc等操作。广泛的用于固定时间窗口的小数据存储。比如过期,数据有效性检测,应用同步等等。由于是全内存操作,所以速度很快,存取速度应该>1000个每秒。目前广泛用与ChinaRen社区,校内,校友录等业务当中。特点:高速高效,低成本,应用广泛。
其他server:
MO_dispatcher:用于短信上行接口的的数据转发,使用TCP。能高速大流量根据业务号码分发到各个应用服务中。目前用于SOHU短信到ChinaRen各短信服务的转发。 sync:用于静态前端同步,分客户端和服务端程序。客户端通过TCP链接和服务端获取需要同步的文件列表,并且通过TCP高速更新本地文件。此同步程序用于多客户端,单服务端。比如一台服务器生成静态文件,同步这些文件到若干客户前端去。特点:门户级静态内容服务器间同步,高效,高速,大流量。目前用于ChinaRen社区的静态帖子。
总结一下:
门户的核心服务,要求是高效率,高密度存取,海量数据,最好还是低成本。不要用数据库,不要用java,不要用mswin。用C,用内存,用文件,用linux就对了。
基于apache2的服务有很多,用于高请求量,快速显示的地方。 1.mod_gen_verifyimg2:
用于显示验证码,使用GD2,freetype。直接在apache端返回gif流,显示随机的字体,角度,颜色等等。用于ChinaRen各个需要验证码的页面,请求量很大。 2.mod_ip2loc
用于apache端的IP->物理地址转换,高速,高效。读取数据文件到内部数据树,高速检索,获得客户端ip的物理地址。用于需要IP自动定位的产品,还有就是数据统计等。比如ChinaRen校内,每个客户端请求都能获得物理地址,用于应用的逻辑处理。 3.mod_pvserver2
ChinaRen社区帖子点击的记录和显示。根据URL,得到帖子ID,通过UDP数据包,统计到bserv系统。并且把结果通过Cookie返回到客户端。html直接用javascript显示点击数在帖子上。解决了点击数量高效记录,高效读取和非动态页面程序显示的问题。 4.mod_online
用于ChinaRen页面上的蜡烛人显示。和onlineserver通讯,得到用户在线状态和其他状态信息。请求量很大,每台前端大概500-800个请求。 5.其他mod 还有一些认证的,访问统计的,特种url过虑跳转的,页面key生成的,还有若干。特点:高速,密集超高请求量。前端分担应用服务器压力,高效。