make
#include
#include
#include
#include
#include
#define DATABASE "yangjian.db"
int main()
{
/*
}
Hash or Btree?
Hash 和 Btree方法应该被用于当逻辑记录号不是用来做主键对数据访问的情况。(如果逻辑记录号是一个secondary key,用来对数据进行访问,Btree方法是一个可能的选择,因为它支持通过一个键和一个记录号来同时的访问。)
Btrees中的键是按一定的秩序来存放的。Btrees应该被用于那些keys存在某种关系的时候。例如用时间做keys,当现在访问8AM时间戳的时候,可能下一个就访问9AM时间戳。也就是在排列顺序中附近的(near)。再比如,用names做keys,我们也许要访问那些有相同last name的,Btrees仍然是一个不错的选择。
在小的数据设置上,Hash 和 Btree在性能表现上没什么差别。在那儿,所有的,或大部分数据设置被放在了cache里面。
尽管如此,当一个一数据设置足够大的时候,会有一些重要的数据页再也装不进cache里了。这种情况下,我们上面讨论的btree在性能表现上就很重要了。
例如,因为在hash中没有排列顺序中附近的机制。所以,cache在Btree中通常比Hash中更有效。Btree方法将产生更少的I/O调用。
尽管如此,当一个数据设置更大的时候,hash访问方法能赢过btree方法。原因是btree比hash数据库包含了更多的元数据页。
数据设置可以变的非常大,以至于元数据开始支配整个cache。如果这种事情发生,Btree将不得不对每次请求都进行一次I/O操作。Cache中几乎没有地方再放置那些真正的数据页了,失去了cache的意义。而因为hash有很少的元数据,可以它的cache照样可以用来放置那些数据页,起到cahche的作用。
当一个数据更更大的时候,以至于每个随机请求,hash和btree几乎都要进行一次I/O操作的时候。在这中情况下,实际上hash只要遍历少树几个内部页(internal pages)就差不多能找到,所以这也是hash在性能上的一个优势。
如果数据设置只是比cache大一点,我们还是条件使用Btree,如果你实在有太大的数据设置,hash也许会更好一些。db_stat公用程序是一个有用的工具,用来监视,你的cache表现的怎么样。
针对我们的应用我只讨论了 Hash or Btree?。Queue or Recno?我就不再讨论了。
太大了会产生很多不必要的i/o,而且影响并发性,因为Btree, Hash and Recn都是对页上锁。太小了会使用溢出页,大量使用溢出页会严重影响性能。所以一般
页的大小都选择和文件系统的I/O块,大小相等。
要设置的足够大,至少能满足一次操作的数据。如果你的cache设的太小,每个新页将要强迫换出least-recently-used page。
Berkeley DB将要重新读一次树的root page对于每次数据库请求。当然cache也不是越大越好,当cache大小增长到一个特定的点时,再增加就不会对性能有什么提高了。当到达这个点时,两件事情发生了。Cache足够大以至于,几乎所有的请求都不用再访问磁盘了就能从cache中得到信息。或则是你的应用程序做一些确实很随机的访问,因此再增加cache对于下一个请求也不会有什么性能上的提高了。第二种情况发生的概率很小,因为几乎所有的应用,都显示了一些,请求的相关联性。
如果cache设定的超过了操作系统的能力,将会使用交换分区,频繁换入换出,会很影响性能。
typedef struct {
} DBT;
Berkeley DB没有为以DBT为参数的,返回的data/key对,或回调函数的字节对齐提供任何保证。
应用程序有责任对齐任何需要对齐的。DB_DBT_MALLOC, DB_DBT_REALLOC 和 DB_DBT_USERMEM标志可能被用来对齐存储在内存中的返回项。
2. 在bulk中取回数据
当从数据库中取回大量记录的时候,那些方法调用经常影响性能。Berkeley DB提供bulk取数据接口,它能有效的提高一些应用持续的性能要使用bulk,必须先为DB->get或DBcursor->c_get指定一个buffer。这个在c api中的实现是通过设置DBT结构的data和ulen域还有flag域被设为DB_DBT_USERMEM来引用应用程序的buffer。DB_MULTIPLE或DB_MULTIPLE_KEY 需要指定给DB->get或 DBcursor->c_get方法, 以使多条记录被返回到指定的buffer中。这两个标志的区别请看手册。
下面函数只看红色标出部分就可以了。示范如何使用bulk。
...................................................................................
int rec_display(DB *dbp)
{
#define
}
................................................................................................
同时还要设置DBT的其他几个值。
doff 数据开始处
dlen 数据长度
当从一个数据库中取回一个数据项时,从doff位置开始的dlen字节,被返回。如果被指定的那些字节不存在,其他存在的字节将被返回。
下面的例子初始化数据项字节长度都是20: ABCDEFGHIJ0123456789
size = 20
doff = 0
dlen = 20
data = abcdefghijabcdefghij
that is, the entire record is replaced.
size = 10
doff = 2
dlen = 15
data = abcdefghij
size = 10
doff = 25
dlen = 0
data = abcdefghij
that is, 10 bytes are inserted into the record past the end of the
current data (\0 represents a nul byte).
for (fail = 0;;) { /* Begin the transaction. */ if ((ret = dbenv->txn_begin(dbenv, NULL, &tid, 0)) != 0) { dbenv->err(dbenv, ret, "dbenv->txn_begin"); exit (1); } /* Store the key. */ switch (ret = dbp->put(dbp, tid, &key, &data, 0)) { case 0: /* Success: commit the change. */ printf("db: %s: key stored.\n", (char *)key.data); if ((ret = tid->commit(tid, 0)) != 0) { dbenv->err(dbenv, ret, "DB_TXN->commit"); exit (1); } return (0); case DB_LOCK_DEADLOCK: default: /* Failure: retry the operation. */ if ((t_ret = tid->abort(tid)) != 0) { dbenv->err(dbenv, t_ret, "DB_TXN->abort"); exit (1); } if (fail++ == MAXIMUM_RETRY) return (ret); continue; } }
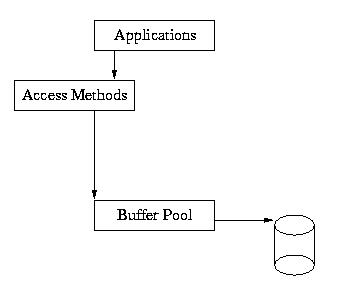
Berkeley DB由五个主要的子系统构成.包括: 存取管理子系统、内存池管理子系统、事务子系统、锁子系统以及日志子系统。其中存取管理子系统作为Berkeley DB数据库进程包内部核心组件,而其他子系统都存在于Berkeley DB数据库进程包的外部。每个子系统支持不同的应用级别。
1.数据存取子系统
数据存取(Access Methods)子系统为创建和访问数据库文件提供了多种支持。Berkeley DB提供了以下四种文件存储方法:
哈希文件、B树、定长记录(队列)和变长记录(基于记录号的简单存储方式),应用程序可以从中选择最适合的文件组织结构。程序员创建表时可以使用任意一种结构,并且可以在同一个应用程序中对不同存储类型的文件进行混合操作。
在没有事务管理的情况下,该子系统中的模块可单独使用,为应用程序提供快速高效的数据存取服务。
数据存取子系统适用于不需事务只需快速格式文件访问的应用。
2.内存池管理子系统
内存池(Memory pool)子系统对Berkeley DB所使用的共享缓冲区进行有效的管理。它允许同时访问数据库的多个进程或者
进程的多个线程共享一个高速缓存,负责将修改后的页写回文件和为新调入的页分配内存空间。它也可以独立于Berkeley DB系统之外,单独被应用程序使用,为其自己的文件和页分配内存空间。内存池管理子系统适用于需要灵活的、面向页的、缓冲的共享文件访问的应用。
3.事务子系统
事务(Transaction)子系统为Berkeley DB提供事务管理功能。它允许把一组对数据库的修改看作一个原子单位,这组操作要么全做,要么全不做。在默认的情况下,系统将提供严格的ACID事务属性,但是应用程序可以选择不使用系统所作的隔离保证。该子系统使用两段锁技术和先写日志策略来保证数据库数据的正确性和一致性。它也可以被应用程序单独使用来对其自身的数据更新进行事务保护。事务子系统适用于需要事务保证数据的修改的应用。
4.锁子系统
锁(Locking)子系统为Berkeley DB提供锁机制,为系统提供多用户读取和单用户修改同一对象的共享控制。
数据存取子系统可利用该子系统获得对页或记录的读写权限;事务子系统利用锁机制来实现多个事务的并发控制。
该子系统也可被应用程序单独采用。锁子系统适用于一个灵活的、快速的、可设置的锁管理器。
5.日志子系统
日志(Logging)子系统采用的是先写日志的策略,用于支持事务子系统进行数据恢复,保证数据一致性。
它不大可能被应用程序单独使用,只能作为事务子系统的调用模块。
以上几部分构成了整个Berkeley DB数据库系统。各部分的关系如下图所示:
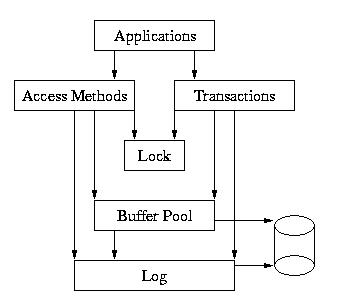
在这个模型中,应用程序直接调用的是数据存取子系统和事务管理子系统,这两个系统进而调用更下层的内存管理子系统、
锁子系统和日志子系统。
由于几个子系统相对比较独立,所以应用程序在开始的时候可以指定哪些数据管理服务将被使用。可以全部使用,也可以只用其中的一部分。例如,如果一个应用程序需要支持多用户并发操作,但不需要进行事务管理,那它就可以只用锁子系统而不用事务。有些应用程序可能需要快速的、单用户、没有事务管理功能的B树存储结构,那么应用程序可以使锁子系统和事务子系统失效,这样就会减少开销。
打印出不再使用的日志文件路径名
监视和检查数据库日志的守护进程
当死锁发生时,退出锁定要求
把数据库文件转换成db_load能认出的文本文件
从db_dump产生的文本文件中创建出数据库文件
把数据库日志文件转换成人能读懂的文本
在发生错误后,把数据库恢复到一致的状态
显示数据库环境统计
把数据库文件转换成新版本的Berkley DB格式
对数据库文件进行一致性检查
许多程序中与db相关的函数都将使db库。
Berkeley DB 环境用来封装一个或多个数据库,日志文件和区域文件。区域文件是共享内存区,它里面包括数据库环境信息像内存池cache页等。只有数据库文件可以在不同的字节序机器间移动,日志文件只能在相同的字节序机器间移动。而区域文件(Region files)常常对于一个特定的机器来说是独一无二的,可能只能在指定的操作系统的某个版本上移动间移动。
Creating a database environment
环境对于bdb的可移植性和灵活性是非常重要的。为了增强可移植性,和快速灾难恢复,建议尽量使用相对路径。建议使用配置文件放置环境参数而不要直接写到程序里,可以避免每次移植时修改和编译源文件。
bdb环境由db_env_create 和 DB_ENV->open接口创建和描述,再需要定制的地方,比如把log文件存储到不同的磁盘驱动器里,或选择一个特殊cache大小, 应用程序描述这些定制信息通过创建配置文件,或者传参数给其他DB_ENV 处理函数。
应用程序首先通过db_env_create方法获得一个环境句柄,然后调用DB_ENV->open来创建或合并数据库环境。这儿有很多选项你可以在调用DB_ENV->open时设置来定制你的环境。这些选项大致可以分为四类:
子系统初始化选项: 这些标志指明哪些bdb子系统将因为环境被初始化,和哪些操作将自动发生当数据库在环境中被访问的时候。这些标志包括DB_INIT_CDB, DB_INIT_LOCK, DB_INIT_LOG, DB_INIT_MPOOL, and DB_INIT_TXN。The DB_INIT_CDB标志为bdb并发数据存储做初始化工作。其他标志初始化单个子系统;也就是说,当DB_INIT_LOCK被指定,应用程序读写在这个环境中打开的数据库时,将使用locking子系统以确保它们不覆盖对方的对数据的改动。
恢复选项:这些包括DB_RECOVER
仅仅DB_INIT_MPOOL标志或者指定其它所有4个子系统的初始化标志(DB_INIT_MPOOL, DB_INIT_LOCK, DB_INIT_LOG, and DB_INIT_TXN)。
db_setup(home, data_dir, errfp, progname)
{
一旦环境被创建,数据库句柄将可能在这个环境中打开,这由db_create函数通过指定特定的环境作为参数来实现。
文件命名,数据库操作,和错误处理等都将因为这个指定的环境而被做。例如,如果DB_INIT_LOCK 或 DB_INIT_CDB 标志被指定,当环境被创建或被合并时,数据库操作将为应用程序自动的执行所有必要的锁操作。
下面是一个简单的例子,在一个环境中打开两个数据库:
DB_ENV *dbenv;
}
Error support
例如:
int ret;
if ((ret = dbenv->set_cachesize(dbenv, 0, 32 * 1024, 1)) != 0) {
}
这儿也有两个附加的错误处理函数:DB_ENV->err 和 DB_ENV->errx。
dbenv->set_errfile(dbenv, errfp);
dbenv->set_errpfx(dbenv, program_name);
if ((ret = dbenv->open(dbenv, home,
}
例如应用程序名为"my_app", 环境的home目录为 "/tmp/home",出错信息将是这样的:
my_app: open: /tmp/home: Permission denied.
my_app: contact your system administrator: session ID was 2
DB_CONFIG configuration file
NAME和VALUE之间用一个或者多个空格来分割。凡是那一行的开头是空格或#的,都将被忽略为注释。
NAME VALUE具体值可以在对用的方法中查到例如DB_ENV->set_data_dir。
DB_CONFIG配置文件的目的是允许管理员定制不依赖于应用程序的环境。例如,可以移动数据库log文件和数据文件到不同的地方,而不用重新编译应用程序。另外,因为DB_CONFIG文件是当数据库环境被打开时读取的,它可以用来覆盖在那以前配置的规则。例如,可以定义一个更合理的cache大小,来覆盖以前已经编译到程序中的值。
dbenv->open(dbenv, "/a/database", flags, mode);
dbenv->set_data_dir(dbenv, "datadir");
dbenv->open(dbenv, "/a/database", flags, mode);
把数据文件放在/a/database/data1和/b/data2,所有其他文件放在/a/database.
dbenv->set_data_dir(dbenv, "data1");
dbenv->open(dbenv, "/a/database", flags, mode);
DB_PRIVATE:如果这个标志被指定,区域将在每进程的堆内存中被创建;也就是说由malloc()返回的内存。
这个标志最好不要指定当一个以上的内存访问环境的时候。因为它很有可能引起数据库腐烂(corruption)和一些不可预知的行为,例如,当
系统V IPC接口被使用。在VxWorks 系统中使用系统内存。在这些情况下,一个初始的段id必须在应用程序中被指定,以确保应用程序不互相覆
在windows平台上DB_SYSTEM_MEM标志问题多多,我就不说了.
任何在文件系统中创建用来支撑区域的文件,将在环境的home目录下被创建。这些文件命名为__db.###(例如,_db.001, __db.002等等)。
当区域文件被文件系统来支撑的时候,每个区域对应一个文件被创建。当区域文件被系统内存来支撑的时候,只有一个文件将仍然被创建,因为这儿必须有一个熟知的名字在文件系统中,以便多进程能定位到环境所使用的系统共享内存。
统计在环境中的共享内存区域可以用db_stat的-e选项来显示。
Security
被bdb数据库环境使用的目录,应该有它自己的许可设置,以确保那些没有适当权限的用户不能访问环境里的文件。应用程序,那些添加到用户
设置 DB_USE_ENVIRON 和 DB_USE_ENVIRON_ROOT标志 和允许在文件命名时使用环境变量都是危险的。在bdb应用程序中用附加的许可(例如,
默认地,bdb总是创建所有者和所在组可读写的文件(也就是,S_IRUSR, S_IWUSR, S_IRGRP 和 S_IWGRP; 或八进制模式 0660 在历史性的UNIX
临时支撑(backing)文件:
如果一个没有被命名的数据库被创建,而cache太小以至于不能在内存中控制这个数据库,bdb将创建一个临时的物理文件使它能把数据库的cache页放到磁盘上,当需要的时候。
在这种情况下,环境变量,像TMPDIR可能被用来指定用以定位那个临时文件。尽管临时支撑文件被创建被只有所有者可读写的。(S_IRUSR 和 S_IWUSR, 或八进制模式 0660 在历史性的UNIX系统上),一些文件系统可能不能充分的保护被创建在随机目录中的临时文件。为了绝对安全,应用程序存储敏感数据在未命名的数据库中,应该用DB_ENV->set_tmp_dir方法用已知的许可(known permissions)指定一个临时目录。
我使用多进程访问bdb数据库环境,这儿有什么方法可以确保两个进程不同时执行数据恢复(recovery )操作吗?或者说,确保其他所有的进程都退出了,可以运行数据恢复了?
很多应用程序组,写一个小的监视程序,来恢复数据库环境,然后执行那些实际上用数据库环境工作的进程。监视程序然后监视工作的进程,如果任何工作进程发生故障推出或其他原因,监视程序将kill所有仍然存活的其他进程,然后执行恢复任务,然后重新这个循环。
255
256
257
如果你把他们当成字符串处理那么他们的排序是糟糕的:
257
254
255
在一个大数在前(big-endian)系统上是:
255
256
257
and so, if you treat them as strings they sort nicely. Which means, if you use steadily increasing integers as keys on a big-endian system Berkeley DB behaves well and you get compact trees, but on a little-endian system Berkeley DB produces much less compact trees. To avoid this problem, you may want to convert the keys to flat text or big-endian representations, or provide your own Btree comparison function.
bdb包括对构建基于复制(replication)的高可用性应用程序的支持。bdb replication组由一些独立配置的数据库环境组成。
组里只有一个master数据库环境和一个或多个client环境。Master环境支持读和写,client环境支持只读。如果master环境倒掉了,应用程序将可能提升一个client为新的master。数据库环境可能在单独的计算机上,在单独的硬件分区上(partitions)一个不统一的内存访问系统上,或在一个单独的server的一个磁盘上。唯一的约束就是,replication组的所有的参与者必须在一个字节序(endianness)相同的机器上(都是大数再前或都是小数在前的操作系统)。我们期望这个约束在以后的版本中会去掉。因为总是用bdb环境,任何数量的并发进程或线程可能访问一个数据库环境。在master环境中,多个线程可能读写这个环境。在client环境中,多个线程可能要读这个环境。
应用程序可能被编写成在master和clients间提供不同程度的稳固性。系统能同步的运行以便复制品(replicas)能保证是最新的,对应于所有已提交的事务。但是这样做可能回招致性能上的很大的下降。高性能解决方案有考虑全局的稳固性,允许clients的数据过时一个应用程序可控制的一段时间。
最后,bdb replication实现还有一个附加的特性去增强可靠性。bdb中的replication实现成执行数据库更新用一个不同的编码路径而不是用标
DB_ENV->rep_elect
DB_ENV->rep_process_message
DB_ENV->rep_stat
DB_ENV->rep_sync
DB_ENV->rep_set_config
DB_ENV->rep_start
DB_ENV->set_rep_limit
DB_ENV->set_rep_transport
Replication environment IDs
应用程序有责任去标志每个进来的传递给DB_ENV->rep_process_message的有适当标识符的replication消息。随后,bdb将用这些相同的标识符去标志发送函数发出去的消息。
Replication environment priorities
每个replication组中的数据库环境变量必须有一个优先权,它指定了在replication组中不同环境间的一个相对的顺序。这个顺序在币桓鰉aster倒掉,在决定选举哪个环境作为新master的时候的一个重要因素。优先权必须是一个非负的整数,但不必要replication组中是独一无
