dnsmasq可以通过配置/ets/hots做特殊域名IP绑定,那么如何在不重启dnsmasq服务的情况下重新加载hosts的配置文件呢?
有两种方式:
1, 使用sighup信号量请求:通过信号量方式每分钟只能重新加载一次。如果hosts文件没有变动同一分钟内多次请求无效。
kill -SIGHUP `pidof dnsmasq`
2. 使用reload方式: 此方式可以随时重新加载hosts文件配置,不管文件是否有变动。
systemctl reload dnsmasq
dnsmasq可以通过配置/ets/hots做特殊域名IP绑定,那么如何在不重启dnsmasq服务的情况下重新加载hosts的配置文件呢?
有两种方式:
1, 使用sighup信号量请求:通过信号量方式每分钟只能重新加载一次。如果hosts文件没有变动同一分钟内多次请求无效。
kill -SIGHUP `pidof dnsmasq`
2. 使用reload方式: 此方式可以随时重新加载hosts文件配置,不管文件是否有变动。
systemctl reload dnsmasq
以前一直用fiddler做http/https代理开发调试,但是在请求一些代理资源的时候往往会被对方服务器返回403,比如微信朋友圈的图片用fiddler是打不开的,调试七牛云的上传时候七牛云会返回403错误,appstore的APP更新也无法访问。
今天找到腾讯前段团队出的一个用node写的代理神器whistle,试用了一下上述所遇到的代理无法访问的资源都可以正常访问了,在功能上比fiddler更简单更容易上手操作,代理规则的编写也非常。
whistle官方文档:https://avwo.github.io/whistle/
安装的话直接使用node 的npm安装神器部署即可,这种部署在同一的开发服务器上比自己本机安装fiddler进行调试更高效,不需要每个人都部署自己的fiddler和正则代理配置。
使用百度云加速一年多,有优点也有不少缺点。依据本人真实使用经验分享,不是软文,根据你网站自身情况来选择是否使用百度云加速。
先说说优点:
1. 机房分布确实很广泛,抗ddos和cc攻击效果有效。
2. 静态缓存cdn效果不错,可控制粒度尚可。
3. 常规的7层攻击基本能检测到,同时可拦截,当然也有很多没有被拦截到,你问我是怎么知道的,因为我后面还有阿里云的WAF安全监测。
4. 大型CC攻击时会自动开启超强防护模式提供验证码拦截方案,对于防护后端程序有效果,但是也有很多时候出现验证码输入正确后还是无法正常访问的问题。
再说说缺点:
1. 2017年10月份开始不管收费还是免费都按照日流量限制,没有以前那么高的性价比。
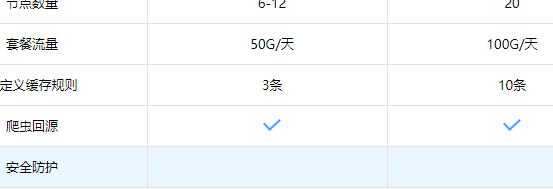
2. 对于流量较大的网站会偷偷植入第三方有米移动广告平台的推广广告js,不过这个行为百度云加速官方会偷偷的做,一般很难发现,大家如果使用免费的云加速要注意了。如下是曾经发现被百度云加速故意嵌入的js脚本:

3. 百度云加速有可能在不通知你的情况下故意停掉你的接入解析,同时清理掉你的所有相关配置项,相当于把你的账号清零。当然前提是他们所认为的可能违背网络安全管理法相关的问题。所以如果你的服务要保证高可用,不管买最贵的企业版还是最便宜的专业版,我还是不推荐你使用百度云加速的服务了。
4. 百度云加速虽然是分布式集群方案,但是我们也遇到了他们服务器故障的情况,当他们集群故障后,他们的DNS解析到新IP的时间有可能超过15分钟。
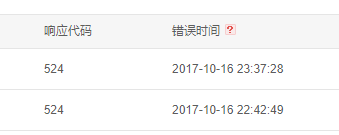
5. 即是你是收费的版本也有可能存在访问接入故障的问题,我们有检测百度站长平台的爬虫统计,有一定概率的爬虫请求失败,爬虫获取的HTTP状态码是524(524是CloudFlare的状态码,大家都知道云加速和CloudFlare之间的关系),但是我们根据爬虫失败的时间查看我们网站原始的nginx日志,却发现返回的状态码是正常的200。如果你的网站需要对爬虫非常友好,那么云加速的收费版本也不一定能帮你多少。
6. 对于收费版本的云加速提供的HTTPS服务,建议大家还是不要用的好,毕竟证书不是那么的可靠和安全,当然专业版目前看是不让你指定你自己的证书的。
最近使用武汉电信老是会在wap的页面上弹出“”“曝光APP”的底部广告,这APP指向的网址是www.chudianyun.com,
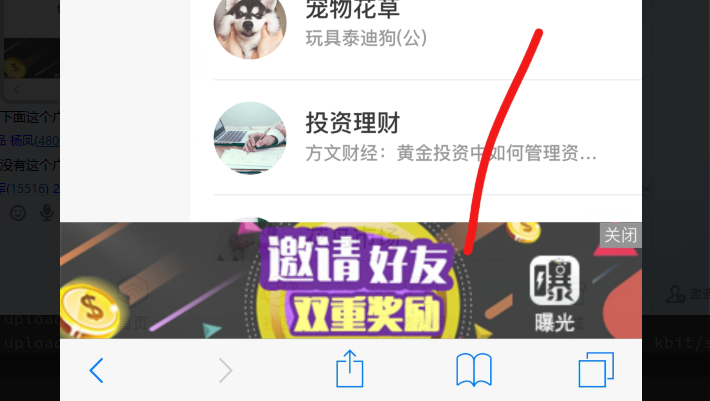
抓包分析是hm.baidu.com这个网页统计接口被HTTP劫持。

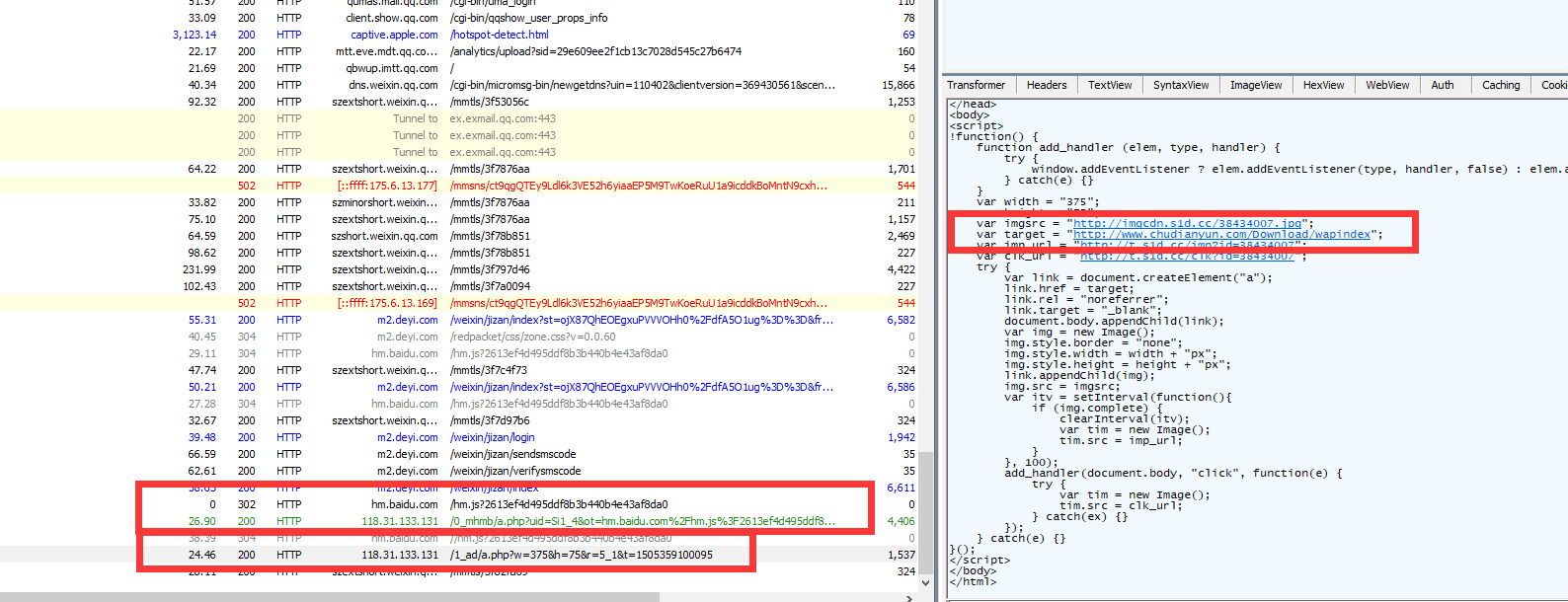
这个劫持够狠的,那么多使用百度统计的,直接修改百度统计js,指向到广告js地址然后插入到wap页面中去,提醒广大使用百度统计的站长将http的统计更换为https。百度的统计代码默认给的是"//"这样的地址,它会随你网页是http还是https自适应,如果你只使用了http协议,那么就强制百度的统计代码引用为https吧,避免被武汉电信的HTTP流量劫持给插入广告.
